Parallels Desktop is a virtual machine software under the macOS system that helps users run Windows, Linux and other operating systems. In September 2021, I started security research on Parallels Desktop, during which I discovered several high-severity vulnerabilities. Unfortunately, in the latest update, my vulnerabilities were patched. I wrote this article to describe my Parallels Desktop research process, as well as the technical details of finding and exploiting vulnerabilities.
中文版Introduction
The version of Parallels Desktop I studied is 17.0.1 (51482), and I clarified some basic logic of this software by slowly groping. The name of the program responsible for running the virtual machine is prl_vm_app. Similar to other virtualization software, the structure is shown below.
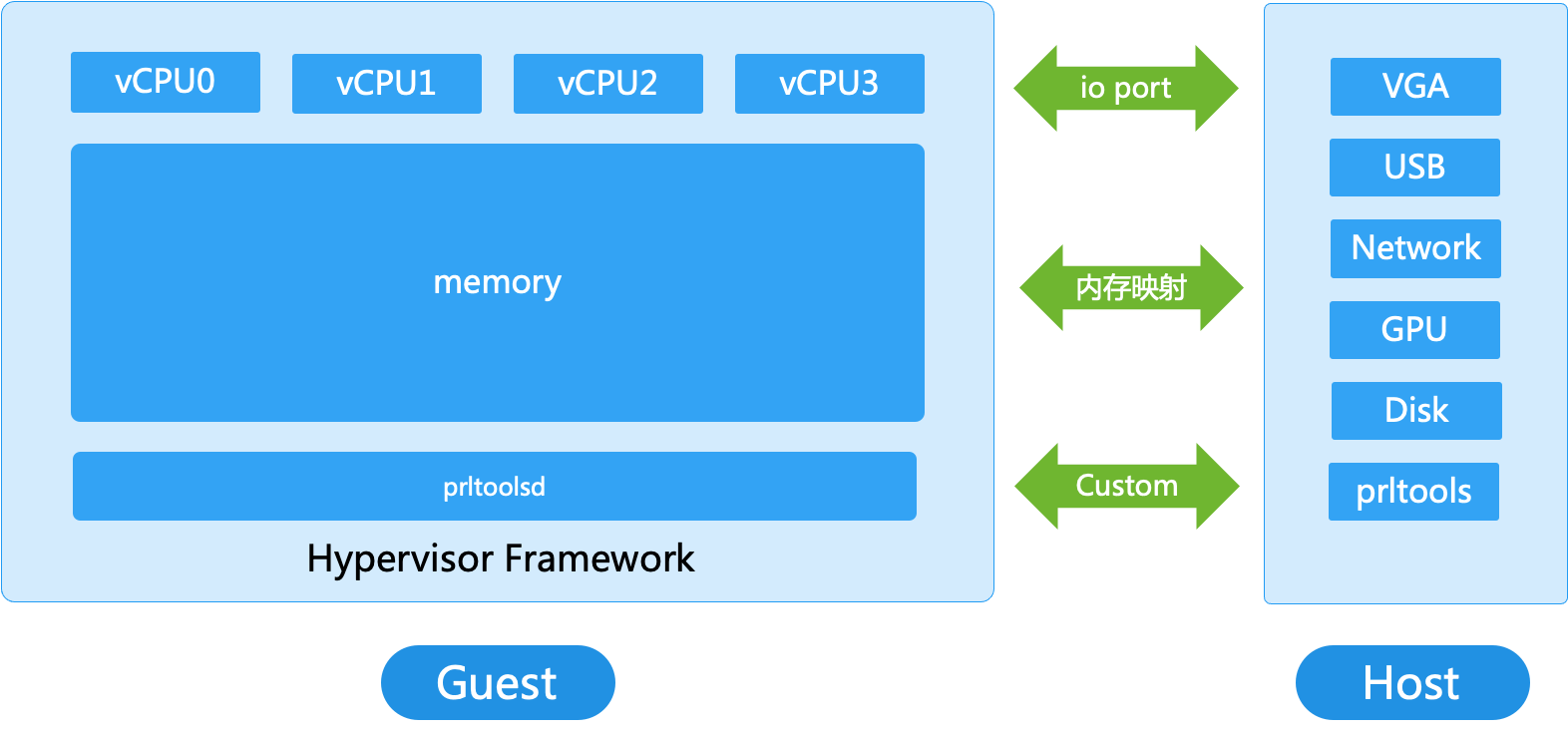
prl_vm_app needs to handle interrupt requests from vCPU, simulate peripheral operations, and call it Host. What we usually call virtual machine escape is to destroy the host application by sending illegal requests on the guest host, and implement code execution on the host.
On a traditional physical machine, the CPU generally communicates with devices through io ports and memory mapping (DMA), and this is the part that software must simulate. At the same time, prl_vm_app also implements some custom communication protocols in order to realize some common functions of virtual machines such as clipboard sharing and file sharing. This protocol generally transmits data through agreed registers and physical memory, and needs to be used in conjunction with the driver developed by Parallels itself. Research by others in the past has found some security issues in protocol processing, and this is a good and easiest attack surface to locate.
Another attack surface is the simulation code of various devices on the Host. The interaction protocol of each device is different. When auditing the code, I need to learn one by one. This is a very time-consuming task. Almost half of the mining process is learning how to properly interact with these devices, and the other half is reverse auditing the corresponding code. The content of my audit is also very simple, mainly whether the index is properly checked, whether there is an integer overflow, whether the memory copy is out of bounds, etc. But these type of bug are easy to find, and previous research work and the security measures of developers will definitely make similar bugs less and less. After fumbling around for a while and getting nowhere in my vulnerability digging, I started looking for experience from other people’s security research.
In the past virtualization research, I noticed a relatively easy vulnerability mode TOCTOU (Time of Check Time of Use). Similar problems have occurred in Vmware products, such as CVE-2020-3981, CVE-2020-3982, QEMU has also been exposed to this problem such as CVE-2018-16872. This is a very easy error during development. In the final analysis, it is caused by Race. The Guest and the Host share physical memory through memory mapping. When the Host checks the requested data, the Guest can modify the data at the same time. Next I will explain it in detail with specific bugs.
Vulnerability Analysis
I found a similar problem in the virtio-gpu device, as shown below, the input pointer is the memory map of the Guest physical memory in the Host, and when processing the VIRTIO_GPU_CMD_UPDATE_CURSOR request, two variables input are read from the Guest’s input ->pos.scanout_id and input->resource_id, check scanout_id on line 8 to see if the array index is out of bounds, and write resource_id into the array on line 16.
1 | ... |
We can create a new thread through the code execution gap from lines 8 to 16, and modify scanout_id to any data, that is, we can write any value out of bounds in the array.
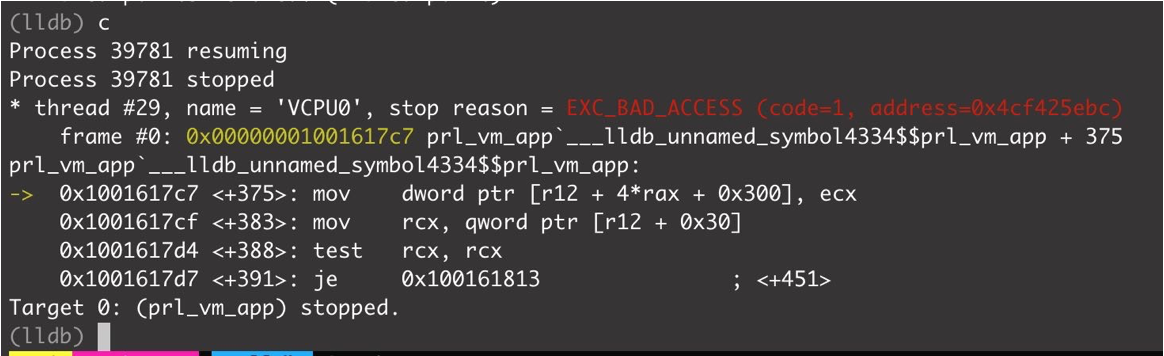
If this scanout_id is modified to an illegal value, it may cause illegal memory access. This is the crash log at that time.
Vulnerability Exploit
At present, we have written arbitrary data with relative offset. Next, I will discuss the construction of information leakage and arbitrary address reading and writing by tampering with the structure a1(gpu_buffer)
1 | struct { |
Address Information Leakage
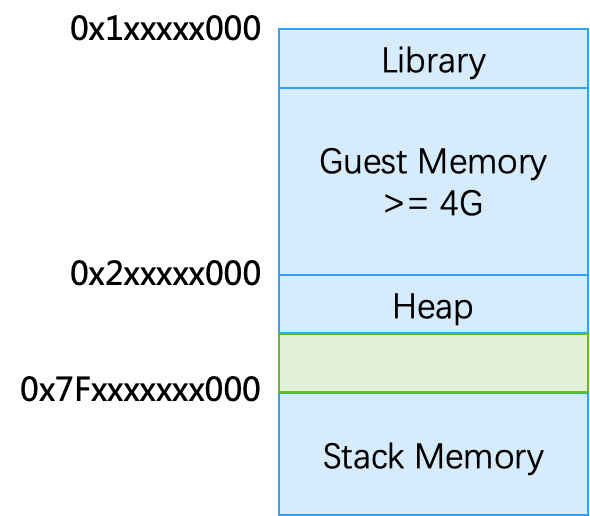
Through debugging, I found that the address space of prl_vm_app is as follows. After the address randomization is turned on, the Image Base starts from a random address of 0x1xxxxx000, followed by the Guest Memory. If the physical memory of the virtual machine is large enough, such as more than 4G, then there is a high probability that some fixed Host virtual addresses (such as 0x200000000) will definitely fall on the Guest Memory.
In the process of GPU processing, queue_result saves the interactive address mapping information. As shown below, the GPU takes the corresponding memory address and data length from the virtio queue, translates it into a virtual address on the Host through gpa_to_hva, and writes it back to mem_handlers.
1 | v2 = a1->cursor_queue.queue_result; |
When exploiting, I modified the queue_result pointer to a fixed constant of 0x180000000, and then triggered any virtio-gpu request, and Host wrote the address translation information to queue_result (the pointer has been tampered with 0x180000000). Then I searched the physical memory of the entire virtual machine for the modified physical page, so as to infer that the Guest Memory Base on host.
1 | uint64_t fake_hva = 0x180000000; |
Arbitrary Address Read
The queue_result is tampered to point to the guest physical memory, which can not only achieve information leakage, but also facilitate subsequent use. Because it saves the address information during interaction, by tampering with the data in it, any address can be read and written.
I used the following gadget, which is a code branch when the GPU handles different requests. The code content from lines 8 to 17 is to write the v19->mem_handlers[0].hva data of the virtual machine back to v19 ->mem_handlers[2].hva. Normally, they hold the addresses translated by gpa_to_hva which tell the device where to read data from and where to write data. Guest and virtio-gpu agree that data is read from v19->mem_handlers[0].hva, and the returned result is written back to v19->mem_handlers[2].hva.
1 | else if ( dword_10101ED68 > 0 ) |
When the request is called, a new thread is enabled again, and v19->mem_handlers[0].hva is modified to any address, that is, any address can be read, and the data can be written back to v19->mem_handlers[2].hva.
Arbitrary Address Write
The method of writing any address is similar to the above. After the address translation of v19->mem_handlers[2] is completed in line 8, I can quickly change v19->mem_handlers[2].hva to arbitrary address that needs to be written through Race. It’s just that compared to reading at any address, the race window is very small. Only after the gpa_to_hva function on line 8 exits and before the assignment of v20 on line 9, modify v19->mem_handlers[2].hva to successfully implement arbitrary address writing. However, this method can be called an infinite number of times, and a few attempts will always succeed.
With arbitrary address read and write, firstly search the Image Base near the Guest Memory Base, find the link library, calculate the system address in libc, and finally implement arbitrary code execution by tampering with the function pointer.
References
- https://www.zerodayinitiative.com/blog/2021/4/26/parallels-desktop-rdpmc-hypercall-interface-and-vulnerabilities
- https://www.zerodayinitiative.com/blog/2020/5/20/cve-2020-8871-privilege-escalation-in-parallels-desktop-via-vga-device
- https://trenchant.io/pwn2own-2021-parallels-desktop-guest-to-host-escape/
- https://zerodayengineering.com/projects/slides/ZDE2021_AdvancedEasyPwn2Own2021.pdf